
In my last blog we covered all event-driven services offered by AWS, the oldest and most used is Simple Queuing Service (SQS). Over the course of this blog, I will first describe queues in SQS incl. the diverse types available, the features and properties related to events, consuming an event, dealing with errors, and monitoring of the queues. Finally, I will wrap it all up with the way pricing works when using SQS.
Queues in SQS
SQS is a serverless queueing service that is used to decouple microservices from each other using events. It is used for one-to-one microservice communication, where the consumer must poll to receive events. This polling mechanism ensures that downstream services do not get overloaded (the queue acts as a buffering layer). Since it is serverless you do not have to provision or maintain any servers, this is all done by AWS. All you must do is create a queue and start producing/consuming the events from it.
Event producers can produce their events to the queue, and event consumers can poll them from the queue at their own pace, preventing consumers from getting overwhelmed. Figure 1 gives an example of how the queues can be used to decouple services.
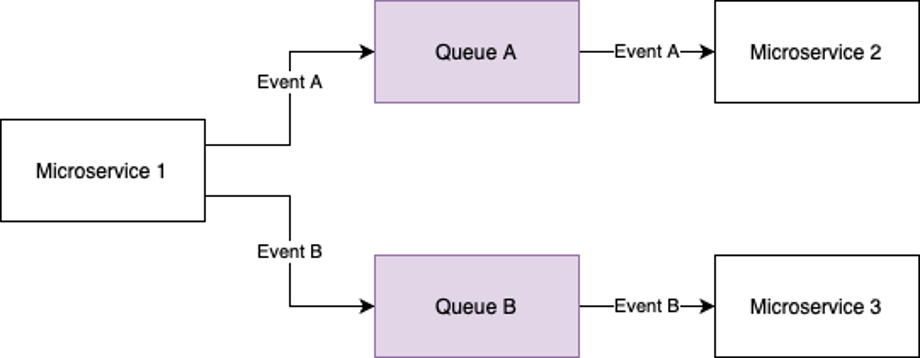
Figure 1: Example of queues used to decouple microservices
SQS stores all queues and events in a distributed fashion for resilience and availability purposes. Queues are bound by a region, but by default spread across availability zones (AZs). Whenever an event is produced, it gets stored across AZs to ensure any local outage (or any other form of AZ-wide downtime) will not lead to the loss of events. All management of this distribution is done behind the scenes by AWS. In case your interested in how this is stored, this page explains it quite well.
Types of queues
SQS offers multiple types of queues which can serve different use cases. The three main types currently available are:
- Standard queues
- First in first out (FIFO) queues
- High throughput for FIFO queues, which are FIFO queues with specific configurations
Besides the main queue types, there are also configurations which make a queue a “delay queue”, and a mechanism called temporary queues. In the following subsections I will go over each one of these types of queues to explain what they are and how they differ from each other.
Standard queues
Standard queues are the default queues offered by SQS, and are basic queues used for decoupling services and for acting as a buffering layer as described in the introduction of this section. This type of queue does have the highest throughput values in SQS, supporting (nearly) unlimited API calls per second.
Although the high throughput is a big strength of standard queues, there are some limitations to them as well. The first being related to delivery guarantees. Standard queues support at-least-once message delivery (meaning that an event will be consumed at least once, but potentially multiple times). To ensure proper state in your landscape the consuming microservices should be idempotent, where they produce the same output when given the same inputs, even when the input is given multiple times. An example of when an event can be delivered multiple times is when one of the servers storing a copy of the event is down when the delete operation is being requested. In such scenarios, the copy of the message isn’t deleted on that unavailable server and as consequence a new poll request can result in the old event being retrieved.
The second limitation to discuss is the ordering guarantee. AWS offers a best-effort ordering guarantee for standard queues, meaning that events will not necessarily be processed in the same order they are produced. If ordering is a requirement in your use-case, FIFO queues are a better fit for you.
FIFO queues
FIFO queues are queues where events are guaranteed to be kept in order, and they can be recognized by their names as it is required for them to end with “.fifo.” It is important to know that the ordering guarantee goes for a subset of the events. Each event produced to a FIFO queue is expected to have a message group ID, showing that an event belongs to a group (for example to the session of a user). All events in a queue with the same message group ID are guaranteed to be processed in order, but events of separate groups can be processed out of order of each other. Figure 2 visualizes the ordering difference between standard and FIFO queues.
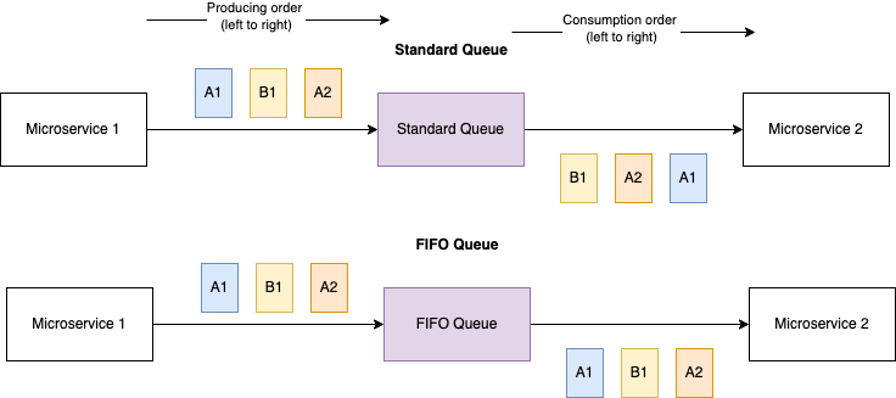
Figure 2: Standard vs FIFO queue ordering. Note that for FIFO the consuming combinations (A1, A2, B1) and (B1, A1, A2) are also possible since A1 is before A2 in those combinations. For standard queues all 6 combinations of the 3 events are possible
When consuming from a FIFO queue, the consumer cannot request a specific message group ID to consume from. Instead, consumers just poll from the queue to receive any message present. However, whenever there are multiple message group IDs present on the queue, SQS tries to return as many events with the same message group ID as possible. This way other consumers can process events with other message group IDs. Furthermore, whenever an event with a certain message group ID is consumed, all future events with the same message group ID will not be retrieved by later polls until either the current event is acknowledged (deleted from the queue) or processing has timed out (processing longer than the configured visibility timeout, more on this later).
Besides ordering, FIFO queues also have a deduplication feature to prevent the same event from getting produced multiple times. There are two ways (which are configurable) for a FIFO queue to detect duplicates. The first approach is content based deduplication, in which SQS uses a SHA-256 hash based on the event body. It uses this hash as the deduplication ID. The second approach is for the producer to explicitly set the deduplication ID value. In both cases SQS will ignore any event it received within the next 5 minutes that has the same deduplication ID.
By combining the ordering guarantee and the deduplication feature, SQS FIFO queues provide an exactly once-processing functionality. However, there are some situations where this is not the case. The most common edge case being error scenarios. When events are not processed within the configured time, or there are consumer errors with retries enabled, events can be processed multiple times.
With all the benefits described above, there are also some limitations to FIFO queues. The main limitation is the throughput. Where standard queues offer (nearly) unlimited API calls per second, FIFO queues support up to 300 API calls per second (per queue, including both produce and consume calls). If you enable batching, this means up to 3.000 events can be either produced, consumed or a mix of both per second (note, batches can have up to 10 events). Luckily, if ordering guarantees are necessary in your landscape, and you need a higher throughput, you can either request a quota increase or you can use a feature called high throughput for FIFO queues.
High throughput for FIFO
What happens when you need the ordering guarantees and the deduplication features FIFO queues offer, but you need higher throughput than FIFO queues offer? For such use cases you can opt for a feature in FIFO queues called high throughput for FIFO queues.
High throughput for FIFO queues can be enabled by setting the following two configurations when creating a FIFO queue:
- Set the “deduplication scope” to “Message group”
- Set the “FIFO throughput limits” to “Per message group ID”
Alternatively, when using the AWS console, you can also check the “Enable high throughput for FIFO” checkmark, which will set the two configurations appropriately.
The way high throughput for FIFO queues works, when setting these configurations, is that it will partition the data per message group. A partition in this case is a subset of the events that is stored, and replicated, together. Events will be spread across the different partitions based on their message group ID. Even though not all message group IDs will go to the same partition, each group will go to the same. Furthermore, AWS will manage the partition lifecycles for us, and will scale in/out based on the request rates per partition and utilization. Figure 3 gives an example of how events will be distributed across partitions.
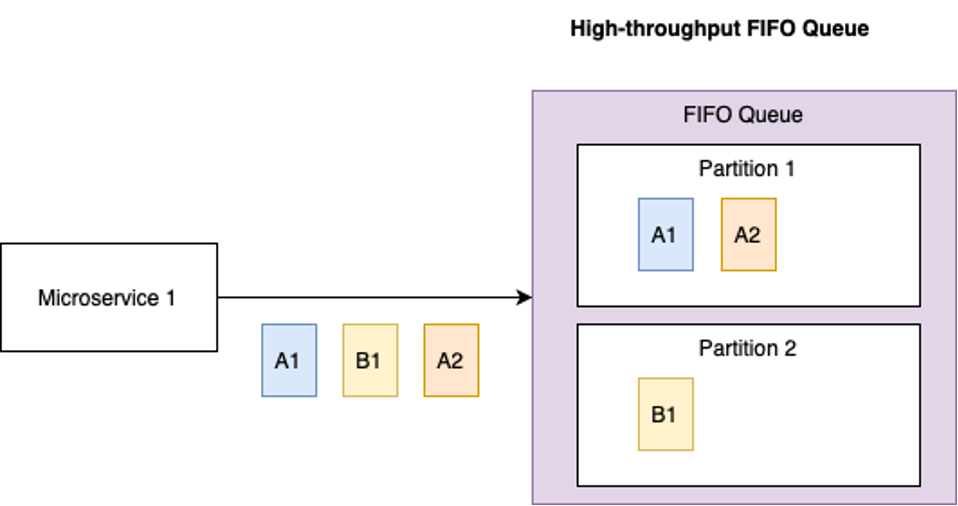
Figure 3: Partitions on high throughput for FIFO queues
When using the high throughput for FIFO queues feature, the throughput of your queue can go up to 6.000 transactions per second (depending on your region), which can be increased to 60.000 transactions per second when using batching. For maximum throughput it is recommended to use a message group ID that has enough diversity, to ensure events get distributed over different partitions. This ensures the events get distributed across partitions evenly which can prevent hot partitions. However, in doing so it is important to keep in mind that ordering is guaranteed within a message group ID, so taking a random value for each event will lead to the loss of ordering.
On a final note, before moving to delay queues, you might wonder why you wouldn’t always use high throughput for FIFO queues when you need the ordering guarantee. Personally I haven’t found any use cases where high throughput mode wasn’t suitable. That being said, if we look at the specific configurations that are set to make a FIFO queue high throughput we see that we need to set the deduplication scope to message group ID rather than the entire queue. This implies that if you have a use case where you need events to be deduplicated over the entire queue, rather than just within a message group, high throughput mode is not suitable for you. Although this sounds like a rather edgy edge-case, because it means you could have the exact same event with a different message group ID without explicitly wanting that, it’s the only use case I can think of not to use high throughput mode when using FIFO queues.
Delay queues
Delay queues are more of a configuration on top of standard and FIFO queues rather than their own queue type. When enabling the delay period, all events sent to that queue will be invisible for consumers for the specified period (default is 0 seconds, with a maximum value of 15 minutes). This configuration can be specified when creating a queue, or on existing queues. However, for standard queues the delay will not be added retroactively to existing events on the queue. For FIFO queues the delay will be added retroactively to existing events. Although use cases for delay queues are rare, they can be used to work around race conditions where the service needs some more time processing the data before consumers can use the event. An example of such a use case would be if you have stored procedures that manipulate the database state, while the service already produced the event (when using event notification for example. Note: this is of course an extreme example for illustration purposes which I won’t recommend implementing like this). Another use case could be when you have a fixed period between stages in your landscape, so adding a default delay could be useful instead of consumers consistently checking when the last stage was executed.
Temporary queues
The last type of queue is the temporary queue.They are short-lived queues that are created and deleted on the fly when needed. This is done using the temporary queue client. Although depicted here as a different type of queue, temporary queues are actually virtually created on an existing queue, essentially becoming a “sub-queue”. Due to it’s nature, it is not recommended to produce events to temporary queues wiith the same message group ID, because this can lead to the events being distributed over multiple temporary queues which will cause an ordering dependency between temporary queues. For this reason it is recommended to not use virtual queues if you need the FIFO functionality.
Temporary queues are most often used when a request-reply pattern is needed, while using SQS as the communication layer. Even though this is often considered an anti-pattern, since SQS (and events in general) are used for asynchronous communication between services, AWS decided to add this functionality anyway because users were using SQS for synchronous communication due to, amongst other things, the following benefits:
- It is often easier setting up a queue rather than the infra needed for secure HTTPS communication.
- Queues are secure and can absorb DDOS attacks out of the box.
Since it is quite rare to have a use case for temporary queues, and it can become quite lengthy to cover them in dept, I will not dive deeper into their mechanics. Instead, for those interested, I would recommend this blog about it.
Event properties
Now that we understand the queues in SQS, let us look at the events. All events sent to SQS have a maximum size of 256KiB, which includes the event itself and its metadata. For events larger than this you could use the AWS extended client library for Java which uses the claim/check pattern in combination with S3 for sharing the large events. Events sent over SQS consist out of three parts: Identifier(s), body, and metadata. Next to these parts, events can also have a message timer and can be sent in batches.
Event identifier(s)
Every event is sent to an SQS queue as a certain number of identifiers, either created by the server (SQS) or provided by the producer of the event. The first identifier to be aware of is the message ID, which is a server generated identifier which is generated and returned by the queue whenever you produce an event. Whenever an event is consumed, a receipt handle is provided with the event. This handle is related to receiving the event, not the actual event (so when consuming an event twice it will have the same message ID, but a different receipt handle). The receipt handle is used to delete events from the queue, meaning you always need to consume the event before deleting it from the queue.
While the message ID and the receipt handle are present for all queue types, there are three more identifiers that are only present when using FIFO queues. The first being the deduplication id. As mentioned earlier in the FIFO section, the deduplication id is used to prevent duplicate events being produced in a span of 5 minutes and can be either provided by the producer or based on the hash of the event body. The second identifier is the message group id. The message group id indicates to which group the event belongs, which is used to preserve the order of events within that group. Finally, there is the sequence number which SQS assigns to each event that is produced. The sequence number is used to maintain the order of events (within a message group).
Event body
The event body is the content of the event you have produced. The body is just a string of the intended data to be shared across services. Good to know, when producing an object/JSON, the consumer should have serialization logic to transform this from a string to an object/dictionary as the actual event will just be a string.
Event metadata
Next to the body, producers can also share metadata about the event along with the body. Examples of metadata that is shared along could be session identifiers and tags to filter events on. There is a limit of 10 attributes that can be added to each event, and each attribute consists of a name, type, and value. Do note that message attributes do count towards the 256KiB event limit.
Besides custom attributes, it is also possible to provide system attributes. This refers to attributes that are specifically used by other AWS services. Currently the only system attribute supported is the AWSTraceHeader, which is a string which refers to the trace header provided by X-ray. System attributes do not count towards the event size limit.
Other Event properties
There are two more event properties that can be interesting when producing events, given certain use cases. The first of them is the message timers. Message timers indicate that an event should be invisible to consumers for a certain period (between 0 seconds and 15 minutes). This can be set by the producer upon producing the event. Do note, FIFO queues do not allow you to set message timers on individual events. If you need delays in a FIFO queue, delay queues can be used, which were discussed earlier in this blog.
The second property to discuss when producing events is batching. SQS supports batches of up to 10 events. Batching can help improve throughput and reduce costs, as all 10 events go over the same API call. There are currently three batch operations: sending events, deleting events, and changing the message visibility. To enable batching, simply use the batch operations instead of the normal ones (for example: SendMessageBatch instead of SendMessage).
Consuming events
Consuming an event goes in three steps:
- The consumer polls from the queue to get any available events.
- When it receives an event, the consumer will process it.
- The consumer will delete the event from the queue, preventing future polls (of itself or of other consumers) from receiving the same event again.
Figure 4 illustrates this process.
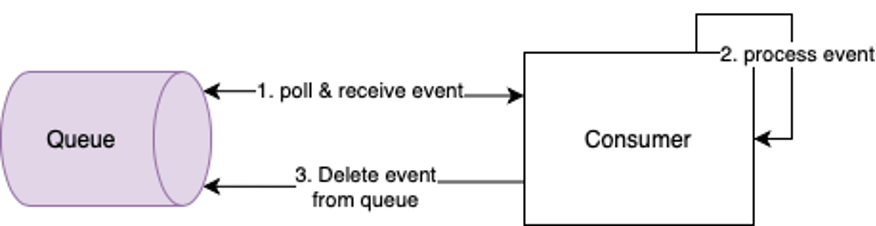
Figure 4: Steps taken when consuming an event
Now you might wonder, but what if another consumer (consumer B) polls the queue while the first consumer (consumer A) is still processing the last event it polled, how do we ensure that consumer B does not receive the same event? After an event is consumed, the visibility timeout kicks in. The visibility timeout is a predetermined time span (30 seconds by default but can be configured to be anywhere within 0 seconds and 12 hours on a queue level) for which the event turns invisible for other consumers while it is being processed. This prevents other consumers (consumer B in our example) to re-process the same event. However, this does mean that the event must be processed and deleted within the span of the invisibility timeout. If for some reason processing the event takes longer than the specified visibility timeout consumers can call the ChangeVisibilityTimeout API to extend it. The time specified in the API call will start counting starting the moment the call is made, not from when the event was consumed.
Finally, I have referred to polling a few times already. By default, consumers apply a mechanism called short polling, which means that it will call the queue and either get an immediate response with events or get an immediate empty response. However, it is often the case that the queue is empty every now and then, meaning that cutting the poll immediately if there are no events is costly. To solve this, and reduce costs, SQS has long polling. Long polling means that the consumer will wait for a certain period to see whether any new events are still coming in before cutting the poll. The maximum configurable waiting period is 20 seconds, which is configurable on the consumer side. It is recommended to always enable long polling for your consumers.
Error handling
You’ve set up your first queue, created the producers and consumers that use the queue, and all is going well. After a little while you start to see some errors happening where events are either not produced or consumed. What now? In this section I will answer that question as SQS has a few configurations to deal with this.
Starting with the producer, whenever you receive an error while trying to produce an event, the best you can do is add retries with exponential backoff. As simple as this may sound, it is important to understand the consequences of this. In rare occasions you can get an error on the producing side, but the actual event has been produced and is available on the queue. When using standard queues this means that retrying the event means that the event is produced multiple times, and thus will be consumed multiple times. Luckily, we already know that consumers need to be idempotent, which will solve this. For FIFO queues this will never happen due to the deduplication id, meaning the queue will ignore the second (or third) time the same event happens (within 5 minutes).
For the consumers, the retrying mechanism is a little different. If the consumer does not delete an event from the queue after processing or takes longer to process an event than the configured visibility timeout, the event will be re-processed upon the next polling cycle. This means that the default behavior of the consumer is to retry the events when an error occurs during processing. Although this is good for resilience, if the event is a poison pill (an event that cannot be processed either due to it being malformed or due to a bug) the event will end in an endless cycle of being consumed and throwing errors.
For standard queues this is non-blocking. Since events from a standard queue can be consumed out of order, the consumers will just continue to poll all events (including the poison pill) and process them, which will (most often) lead to the valid events being processed and the poison pill repeatedly failing until the queue retention period (which can be configured from 1 minute to 14 days) eventually cleans up the invalid event. For FIFO queues impact is bigger. Since events of a certain message group must be processed in order, an invalid message will block the rest of the message group to be processed until the invalid message is either processed successfully or removed by the retention policy (which can have an impact on the consuming order).
As you can imagine by now, even though the consumer impact is limited, it can have a serious impact on both your performance and your costs. Repeatedly processing an invalid event costs resources, and for FIFO queues even prevents the rest of the message group from being processed. To prevent the invalid event(s) from being repeatedly consumed for eternity it is recommended to set up a dead-letter queue (DLQ) where these events can go to.
A DLQ is a second queue where SQS can automatically send events to that cannot be processed properly. This queue must be of the same type as the original (source) queue (so if the source queue is a FIFO queue the DLQ should be a FIFO queue as well). Since the DLQ is a secondary queue, it must be created up front and can only then be configured to act as the DLQ for the source queue. After you have created the DLQ and configured it to act as such, you can setup the redrive policy, which will specify under which conditions an event should move from the source queue to the DLQ (for example: after it has been consumed and processed unsuccessfully 3 times). Do be careful with the conditions you set, because setting it too low (1 failure for example) will increase the chances of false positives (e.g., sending a valid event that failed due to a network error to the DLQ), and setting it too high can lead to the higher costs/lower performance mentioned earlier.
After the event is sent to the DLQ, you can inspect the event (consume it without deleting it) to see why it caused an issue. After finding and solving the issue (assuming it was an issue in the source code of the consumer which has been fixed), you can use the redrive to source API to send the event back from the DLQ to the source queue, to allow it to be reprocessed. There are some things to keep in mind during the process of moving the events:
- When the event is moved to the DLQ, it keeps the original enqueue timestamp, meaning that the retention period of the DLQ starts counting from the moment the event was originally produced. Do make sure the DLQ retention period is higher than the source queue (or just as high if you have it set to the 14 days).
- When events are moved back to the source queue, they will be seen as “new” events, with a new message id, enqueue time and retention period.
Before moving the next section, two things to keep in mind whether using a DLQ suits your use case or not:
- For standard queues it is good to use a DLQ, unless you really want to keep retrying an event until it succeeds or expires.
- For FIFO queues, do not use DLQs when the system produces a different outcome if events are not in order. In such cases checking the error and fixing it forward is a better solution (even though it does make the operations more difficult)*.
*Main reasons why DLQs are not recommended for FIFO queues are:
- You can’t redrive back to the queue out of the box, meaning you’ll have to implement this yourself which can be tricky
- You will need some custom mechanism that routes all events with the same group ID, after the failed event, to the DLQ until the issue is resolved and all events of that group can be driven back to the original queue (in order), which also has to be custom build
Metrics and monitoring
We know how to deal with errors now, so let us see how to monitor the activities in the queue(s). The first AWS service we can use for monitoring purposes is CloudWatch. By default, SQS pushes multiple metrics to CloudWatch, which can be accessed through the management portal in SQS and in CloudWatch (where you can also create dashboards and alerts based on the metrics), through the SDK or through the CLI. It is important to know that metrics are only gathered for queues that are active. A queue in SQS is said to be active when it contains events for up to 6 hours. After those 6 hours the queue is marked as inactive, and no metrics are gathered. After a queue is activated (again), it can take up to 15 minutes before metrics are being gathered again. Some metrics that are gathered are:
- Number of events in the queue
- The age of the oldest event
- Number of empty poll responses
- Number and size of the events sent
The full list of metrics can be found here.
The second AWS service used for monitoring is CloudTrail. All API calls made to SQS are captured in CloudTrail as logs. These logs can, amongst others, be used for security monitoring. Some examples could be seeing whether unauthorized people/services have access and perform operations the queue for example, or to figure out who deleted the queue on production. Some examples of operations that are being logged in CloudTrail are:
- Creating or deleting a queue
- Setting attributes or tags to a queue
- Sending events to the queue
The last service I want to discuss regarding monitoring is X-Ray. X-Ray can be used to trace events throughout the various AWS services and microservices. As indicated earlier, we can add the AWSTraceHeader message system attribute to the event to ensure that X-Ray traces the event through the system. Subsequently we can use the management console to view the connections between all services (incl. SQS) used in your event flow.
Pricing
Before wrapping up, the last subject I want to discuss is the pricing model of SQS. SQS has quite a big free tier, serving the first 1 million requests for free each month. It is good to understand the definition of a request here: every action taken on a queue (sending, receiving, and deleting events, but also increasing the visibility timeout for example) is counted as a request. The size of a request is set at 64 KB, meaning that sending an event of 256KB is counted as 4 requests.
FIFO requests are charged at a higher rate than standard requests. The FIFO requests are sending, receiving, deleting, and changing visibility of messages from FIFO queues. All other requests (even on FIFO queues) are charged at the standard rates. Finally, you also pay for data going in and out of SQS. All data going into SQS is free of charge. For data going out of SQS you pay per GB, with rates based on the volume. There are some exceptions to this rule: data going from SQS to either AWS Lambda or EC2 in the same region is free of charge. For more information, and the current rates, you can visit here. Furthermore, I found this blog on SQS pricing, including how to be as cost efficient as possible, quite helpful in understanding the pricing model of SQS.
Wrap up
That is all for the SQS deep dive, by now you should know all about it! Stay tuned for future blogs where I will do similar deep dives into SNS, Kinesis Data Streams (KDS), Managed Streaming for Apache Kafka (MSK), and EventBridge. Besides that, I will also give some practical code examples on working with all of them (incl. SQS)!