
In one of my previous blogs I discussed different event strategies, describing how communication between microservices can be designed to facilitate (work)flows in your system. However, while knowing and understanding the communication strategy is important, the blog did not touch upon the key component in an event-driven architecture: the event service. There are lots of event services out there, each with their own strengths and limitations which are important to be aware of when selecting one for your use case.
In this blog I will describe some of the different event services that AWS offers and list some of the use cases that can be fulfilled with them. The services I will cover are Simple Queue Service (SQS), Simple Notification Service (SNS), Kinesis Data Streams (KDS), Amazon Managed Streaming for Apache Kafka (MSK), Amazon MQ and EventBridge. After describing the event services, I will finish with some other streaming features AWS offers and a short wrap up.
In the context of this blog AWS services that are used to deliver events between systems and/or services will be referred to as event services, even if not officially positioned by AWS as such. At the start of each subsection, I will add a small callout to prevent any confusion. Finally, I do assume familiarity with event-driven architectures and fundamentals of event brokers.
Event Services on AWS
The most common AWS services that are used as event services are Managed Streaming for Simple Queueing Service (SQS), Simple Notification Service (SNS), Kinesis data streams (KDS), Apache Kafka (MSK), Amazon MQ, and EventBridge.
While all these services provide a way to get events from the producer to the consumer(s), they all have a different mechanism and feature set, making each one of them suitable for different use cases. In this section I will go over the services, describe how they work and what use cases they can be used for.
Simple Queueing Service (SQS)
Let us start with the Simple Queueing Service (SQS). SQS is (one of) the oldest services provided by AWS. SQS is a serverless service, meaning that you do not have to provision nor maintain any capacity. Do note that although referred to as an event service in this blog, SQS is a queueing system which means communication between services via SQS is one-to-one (no publish and subscribe functionality).
On a high level, the way SQS works is that producers can push their event on a queue, and consumers poll from it. After polling an event, the event becomes “hidden” for future polls for a set period (also known as visibility timeout) in which the consumer can process the event. After the consumer is done processing, the consumer issues a DeleteMessage call to the queue to remove the event and prevent others from re-consuming the same data. If the consumer of the event does not remove the event from the queue after the visibility timeout expires, the event will be retrieved again at the next poll.
Because it supports re-reading an event (that has not been removed) and polling by consumers we can consider SQS to be a durable queue. Furthermore, by allowing the consumers to poll, events can be processed at a pace that the consumer can handle without overwhelming it. Also, even though SQS is a queuing service, it does not guarantee ordering when using the standard queues (it provides best effort ordering). However, if ordering is really a hard requirement, FIFO queues can be used instead.
FIFO queues do provide event-ordering guarantees (except for edge cases where events that do not get processed get sent to a Dead Letter Queue). However, the throughput for FIFO queues is lower than standard queues. Standard queues have virtually no limit on throughput, while FIFO queues have a limit of 300 transactions per second, which can be increased to 3000 transactions per second (300 API calls with batches of 10) by enabling batching. Also, FIFO queues have an exactly once delivery guarantee for events produced within 5 minutes. It does so by deduplicating the messages upon arrival in the queue. The deduplication can be configured to either deduplicate based on the hash of the content (SQS will do the hashing and matching for you) or by adding a unique deduplication ID to the event.
Now you might wonder what if ordering is critical to my application, but I have a throughput higher than the values defined above? For use cases like that AWS introduced high throughput for FIFO queues! All FIFO queues can be configured to support high throughput by setting the configuration “Deduplication scope” to ” Message group” and “FIFO throughput limit” to “Per message group ID”. With these configurations set, the events will be partitioned based on their group ID. Each partition will have a maximum throughput of 3000 (with batches of 10), or 300 without batching. Also, SQS will automatically scale the number of partitions up or down as needed based on utilization. Finally, by ensuring that you have a well distributed message ID you can get the best out of this feature.
Finally, some other characteristics of SQS are:
- It is highly available by default. AWS stores the queues, partitions, and messages across multiple AZs within a single region
- Default queues do not have FIFO ordering guarantees, instead they have a best effort ordering guarantee. If ordering is a critical factor to your application, you can use FIFO queues as these do provide ordering guarantees
Although the list of supported features is quite lengthy, there are some limitations:
- FIFO queues have limited throughput compared to standard queues, which can be overcome by using high throughput queues
- It does not support pub-sub, although SQS can be combined with SNS to enable pub-sub using the fanout pattern
- A queue is a basic concept where there is a 1-to-1 relation between producer and consumer, so if you have a lot of different events in the landscape, you will likely end up with a lot of queues as well
Some use cases were using an SQS queue could be beneficial:
- Decoupling user interaction from (batch) processing logic
- Replacing already existing direct (e.g., HTTP) communication between services
- The need for a buffering layer for work processing, preventing downstream services from getting overwhelmed
Simple Notification Service (SNS)
Just like SQS, SNS is a serverless service provided by AWS. As the name implies, SNS is used to deliver notifications. Some of its prime use cases are to send push notifications to users (on their mobile phone), send emails or SMS messages. However, SNS also supports pushing notifications to other application services like AWS Lambda & AWS SQS, meaning that it can serve as an event service as well.
SNS has the notion of topics to which producers can produce and consumers can consume. An event produced to a topic will be sent to all consumers subscribed to that topic (also referred to as subscribers), meaning that SNS supports the fanout pattern. However, SNS works with a push mechanism where all the events get pushed to the subscribers. This means that it does not serve as a buffering layer between services, but by combining it with SQS you can get the best of both worlds.
By default, subscribers of a topic will receive all events produced to that topic. In case a subscriber is only interested in a subset of the events, it is possible to assign a filtering policy. Filtering policies are written in JSON and can be applied to both the message attributes (default), as well as to the message body (if configured). Furthermore, filters are inclusive which means that only events that match the filter will be pushed to the subscriber (see Figure 1 for an example).
 Figure 1: example of SNS filtering policy (taken from AWS documentation)
Figure 1: example of SNS filtering policy (taken from AWS documentation)
Even though SNS uses a push mechanism, it does have at least once delivery guarantee with the condition that the consumers are available to push to. If a consumer is unavailable it will retry for up to 14 days (default is 4 days) until it works, otherwise it will not be delivered. This means that, even though there is a promise of guaranteed delivery, there are edge cases where events can get lost. In case you want to increase the chances of events being delivered, it is possible to configure an SQS queue to function as dead letter queue. In doing so the events that cannot be delivered can be stored in the queue for later reprocessing.
Finally, SNS does not give an ordering guarantee by default, but just like with SQS queues, it is possible to create FIFO topics which do have an ordering guarantee. These are most often used when the consumers of the SNS topics are SQS FIFO queues (since only SNS FIFO topics can push to SQS FIFO queues) and have the same ordering guarantee as SQS FIFO queues. By leveraging SNS FIFO topics with SQS FIFO queues you get both the ordering guarantees as well as the publish and subscribe functionality in your landscape. Do note that SNS FIFO topics have a lower throughput than SQS FIFO queues. SNS FIFO queues support 300 messages per second or 10MB (whichever comes first).
To summarize the use cases where SNS can be used:
- Send push notifications to mobile users
- Send messages to users via email or SMS
- Parallel processing of events using the fanout pattern
Kinesis data streams (KDS)
The third event service on the list is Kinesis data streams. Kinesis data streams is a serverless event service, that is tailored towards processing data streams (for example log data or events). It has the notion of streams and shards.
A stream is a collection of similar events that can be logically grouped together. A stream consists of 1 or more shard(s), which are queues where all the events (also referred to as “data record” in Kinesis terms) land. A producer of an event produces to a shard within a stream. Consumers subscribe to a stream and consume from 1 or more shards. In case there are multiple replicas of a consumer, each will be assigned a certain subset of the shards (meaning that the maximum number of parallel consumers is equal to the maximum number of shards). Besides that, data consumed from a single shard will always be in order as the shards are queues. Finally, KDS supports the publish and subscribe pattern out of the box, so multiple applications can read from the same streams/shards.
KDS is a durable event service that can keep events for up to 365 days (default is 24 hours). During this period, each consumer can re-process the events if needed. Consumers do so by simply requesting the event of a specific shard at a specific index (checkpoint). However, KDS does not keep track of the latest index each consumer read last. This means that consumers are responsible for keeping track of what the next event is they should poll for. Luckily, the Kinesis Client Library (KCL) has this build in, by leveraging a DynamoDB table. Since the client is responsible for polling the events at the position they want, KDS can guarantee an at-least-once-delivery model (which is also how KCL is implemented).
KDS has two capacity modes that it can be configured: provisioned and on-demand. For provisioned mode you will have to scale the number of shards up or down manually using either the AWS management console, the CLI or one of the SDKs (or automate it using CloudWatch and Lambda for example). On the other hand, when using on-demand mode AWS will ensure that the number of shards will scale up or down automatically based on the data volume and traffic going through the stream. There are some differences in terms of quotas between the two capacity modes (although most of them are soft limits that can be increased by opening support tickets):
- By default, you can create up to 50 on-demand streams, and unlimited provisioned streams per AWS account. The number of on-demand streams can be increased by opening a support ticket.
- On-demand streams do not have an upper limit in terms of number of shards, however on-demand mode has a default limit of 500 shards per AWS account in us-east-1 (North Virginia), us-west-2 (Oregon) and eu-west-1 (Ireland). For all other regions, the default limit for provisioned mode is 200 shards. To increase this limit, you can open a support ticket
- On-demand streams have a default throughput of 4 MB/s write and 8 MB/s read. This will scale up automatically to 200 MB/s of write and 400 MB/s read capacity. If needed, a support ticket can be opened to increase this number to 1 GB/s write and 2 GB/s read capacity. Provisioned mode has no upper limit to the throughput, as the throughput is determined per shard. Each shard can support up to 1 MB/s or 1000 messages of write and up to 2 MB/s or 2000 messages of read capacity. If more throughput is needed, simply scale up the number of shards.
If the read throughput described above is not sufficient for your use case, you can also leverage the enhanced fan-out consumers feature provided by KDS. When using enhanced fanout-consumers the read throughput increases from 2 MB/s per shard, to 2 MB/s per consumer. It also changes the interaction pattern between the consumer and the shards from polling to pushing (the shard will push data to the consumer). However, to prevent the consumers from becoming overwhelmed, there is still an acknowledgement of bytes received sent from the consumer to the shard. Whenever the consumer fails to acknowledge, KDS will stop pushing data to it until the next acknowledgement comes in. Do note: the client still needs to keep track of its checkpoint in case of scaling out or restarting the consumer.
Some final notes on KDS before looking at its use cases:
- Events can have a maximum size of 1 MB
- KDS can be connected to Kinesis Data Analytics (KDA), for real time analytics, and Kinesis Data Firehose (KDF), for loading data into data lakes and/or analytics services
Looking at the use-cases where KDS would excel, they are:
- Event streaming applications (for example streaming log, click or IOT data)
- Data analytics ingestion platform (when combined with KDA or KDF)
- Data processing pipelines
- Delayed processing (up to a year after producing the event)
- Applications with the need for publish and subscribe, with ordering guarantees and parallel processing
Managed Streaming for Apache Kafka (MSK)
Next up is Managed Streaming for Apache Kafka (MSK). As the name indicates, this is a managed version of Apache Kafka, meaning that all Kafka APIs work out of the box. This makes it an excellent choice of broker if your system is already using Apache Kafka and you are migrating to AWS, or if you are using AWS currently but do not want vendor lock-in on the broker level.
Apache Kafka has the notion of topics and partitions. A topic is a logical grouping of events (like a stream in KDS), and a partition is a queue within a topic (like a shard in KDS). Events are produced to specific partitions within topics based on either the event key, a custom partitioner or randomly assigned. It is important to note that if ordering of a subset of events (for example all events of a specific user should be in order), then a partition strategy that enforces the same partition for that subset is important. Furthermore, MSK is managed. This means that the underlying resources still must be provisioned, but after provisioning they will be managed by AWS. Finally, with the default configurations MSK supports at least once delivery, but consumers can be configured to support exactly once delivery as well. Pulling this together, some use cases for choosing MSK as your event service would be:
Although there are similarities between KDS and MSK from a functional point of view (streams & shards vs topics & partitions), there are also some key differences:
- MSK is a managed service, meaning you still must provision and size the underlying resources, although the provisioned resources will be managed by AWS
- The throughput in MSK is determined by the provisioned broker type instead of the number of shards
- There is no maximum retention limit, events can be retained forever
- The index (offset in Kafka) of each consumer (group) is stored and managed at the broker side instead of at the client side
- The maximum event size is configurable to be higher than 1MB (although this is a bad idea, for big events I would recommend using the claim/check pattern)
Some use case for choosing MSK would be:
- High throughput application
- Events that need to be retained (and potentially replayed) for longer than 7 days
- Producing events of big sizes (> 1MB)
- The needs for out of the box publish-and-subscribe support
- Migrating a system that already uses Apache Kafka to AWS
Amazon MQ
Amazon MQ is a managed event service that provides compatibility with multiple event services that use the one of the following protocols: AMQP 0-9-1, AMQP 1.0, MQTT, OpenWire, and STOMP as well as brokers that rely on API calls like JMS. Currently Amazon MQ supports two engine types, which are Apache ActiveMQ and RabbitMQ.
Although there is no explicit distinction between standard and FIFO queues in Amazon MQ, it is possible to set up ordering guarantees. This can be done by either an exclusive consumer, or by using message groups. When setting this up, what will happen is that the events will be distributed over the consumers based on the message group. As ordering is guaranteed per group, you will have the FIFO behavior. This blog explains in detail how to set this up.
Furthermore, as Amazon MQ is a managed service, maintenance on either the hardware, or the supported broker version can have an impact on its availability. AWS will handle all hardware updates to the brokers, and for the software maintenance you can configure it to either have them done automatically as updates become available, or to do it manually. For the automatic updates of both the hardware as well as the software, it is recommended to run the system in high availability mode, so that each AZ will get its updates once at a time, minimizing downtime.
The most frequently occurring use cases for using Amazon MQ is if you are already using RabbitMQ, Apache ActiveMQ or JMS (or similar brokers) and want to migrate to AWS with minimal impact.
EventBridge
The last service on our list is EventBridge, which is an evolution of CloudWatch Events. Just like SNS, EventBridge is serverless, and uses a push mechanism to its consumers. It consists of event buses (fanout) and event pipes (point to point). Each account has a default event bus, to which AWS services push events out of the box, but custom event buses can be set up as well. A custom event bus can be created for custom events (in case you do not want these mixed with the system events), but also for capturing third party events (from partner SaaS solutions like Buildkite or Datadog). Furthermore, each event bus can have up to 300 rules set up (at the time of writing). Finally, EventBridge also supports scheduled (cron-based) triggers, meaning it can serve as a serverless trigger for scheduled actions.
Event buses route the events based on user-defined rules, which are patterns defined in Json to which events can match (see Figure 2 for an example). Based on the rules, EventBridge can be configured to push the event to specific targets. These targets can be AWS services, HTTP endpoints or other EventBridge event buses. Pushing the events to other event buses is not restricted by region or account, making EventBridge a solution when events need to go cross-account (having different teams/systems on each account for example). Each rule can have multiple targets, allowing for a fanout pattern as well. Do keep in mind that event buses do not provide any ordering guarantees, so consumers should handle ordering (if needed) themselves.
 Figure 2: Sample event with a matching event rule
Figure 2: Sample event with a matching event rule
Before events get pushed to their targets, it is possible to transform their format using the input transformation functionality. This can be leveraged for stripping fields from the input or masking sensitive information for example. Like the event rules, the input transformations are also defined using a JSON syntax.
Besides the input transformations, EventBridge has a built-in schema registry. The schema registry can be configured to automatically detect the schema based on incoming events, but schema’s can also be predefined. Do note, the registry is primarily used to analyze the event structures coming in and to optionally generate code based on the schemas. At the time of writing, there is no validation on whether the events match the schemas build-in.
As mentioned earlier, EventBridge also has event pipes. Pipes can be used for point-to-point communication between services and provide an ordering guarantee. Like event buses, input. can be transformed and filtered before they get pushed to the targets.
Before wrapping up the section of EventBridge, the last feature I want to highlight is durability. EventBridge supports archive and replay functionality. This can be leveraged for error handling/retries for example. Just like event target routing, event rules must be created to determine which events to archive. For each rule you can also configure the retention period of the events (up to infinite if events should not be deleted). Once archived the events can be replayed based on the archive (which events), the start- and the end time. Furthermore, you can also specify which event bus and to which rules on that bus the events must be replayed to, limiting the number of consumers that the events will get pushed to again.
Use cases for using EventBridge would be:
- Transfer events between accounts or regions (and ordering is not a requirement)
- Capture and handle system events (security monitoring for example)
- Need for a schema registry to analyze the events going through the system and generating consumer code based on the schema
- Need for input transformation, like masking sensitive data before it goes to other accounts
- A trigger for cron jobs
- Event ordering is not a critical factor in your application
Summary
Before continuing to the other streaming mechanisms, I would like to present a summary of the event services discussed so far. This summary can be found in Figure 3.
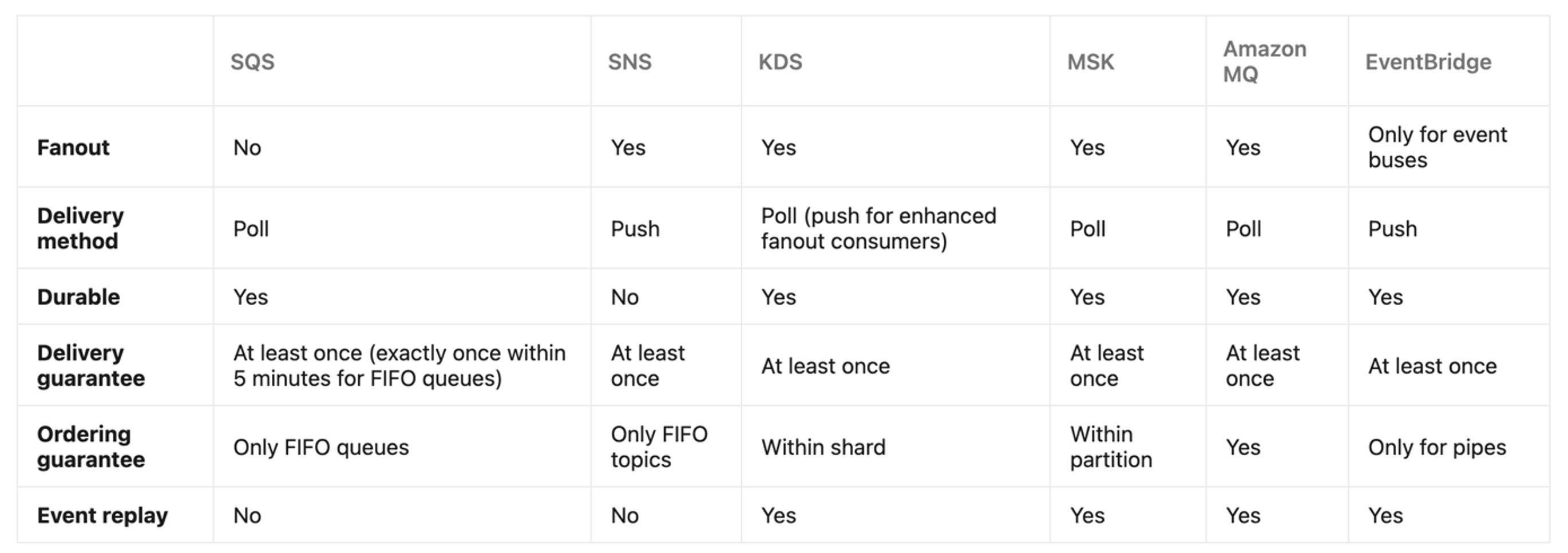 Figure 3: Summary of the event services on AWS
Figure 3: Summary of the event services on AWS
Other streaming mechanisms
For the last section of this blog, there are two other streaming mechanisms I would like to cover which are S3 event notifications and DynamoDB streams. Both services allow for out-of-the-box producing of events whenever something changes with regards to the items stored. While this is usually considered more of a change data capture mechanism rather than an event service mechanism, I feel like these mechanisms can be leveraged in an event driven landscape like event services (or in combination with event services).
S3 event notifications
S3 event notifications can be leveraged to emit events whenever something happens to an object in the S3 bucket. Some examples are new object creation, object deletion, S3 lifecycle events and restoration of events. S3 events can be configured to be sent to SNS topics, SQS queues, Lambda functions and EventBridge. Do note that for SNS and SQS, FIFO topics/queues are not supported. For SNS, SQS and Lambda, you must enable the bucket and the type of events you would like to stream, for EventBridge this is not the case as EventBridge can be configured to pick up the service events.
The S3 event notifications provide at least once delivery guarantee, however, to ensure all events are triggered it is important that versioning is enabled on the bucket. Without versioning, some events can get lost when uploading an updated version of an object to the bucket. Finally, by connecting it to SNS & SQS (using the fanout pattern) this means that every update happening to the bucket can be automatically delivered to all interested consumers.
DynamoDB streams
DynamoDB streams work in a similar fashion to S3 event notifications in that every change made to items in the DynamoDB table is automatically added to a stream, which functions as a change log, which can be consumed by other services. However, as opposed to S3 notifications, the data streamed by DynamoDB can only be directly consumed by compute services (like AWS Lambda). To connect it to other event services, like SNS or SQS, a custom lambda connector must be added which simply consumes from the DynamoDB stream and produces to the event service.
Out of the box DynamoDB streams support publish and subscribe, as its setup is like KDS. Furthermore, instead of using the low level DynamoDB API, it is possible to add a KDS connector to the streams which will allow consumers to consume events from the stream using the Kinesis Client Library.
Wrapping it up
In this blog we have touched upon the various event services provided by AWS and when they can be used. If you are interested in how these services work on a deeper level stay tuned as I will write deep dive blogs on how they work & how to integrate with them using lambda in the coming period!