
Introduction
Artificial Intelligence (AI) currently enjoys widespread popularity, with organizations exploring its applications across various domains, including chatbots and image recognition. AI is leveraged to enhance operational efficiency, reduce costs, and create new business opportunities. However, despite the enthusiasm surrounding AI, it can be difficult to bring it into production, where it can solve real-world business challenges. For example, according to Gartner, only 54% of the projects within organizations that are using or planning to use AI, make it from pilot to production. This is where Machine Learning Operations (MLOps) plays a crucial role.
Think of MLOps as DevOps for AI — a set of practices that aims to develop, deploy, and maintain machine learning models in production, reliably and efficiently. MLOps helps organizations deliver and apply high-quality models faster and with fewer errors.
MLOps is getting a lot of attention, much like AI. New MLOps tools are released almost daily, and many blogs are written about them. People have high expectations that these tools are magic bullets to run models in production. However, MLOps is not just about the tools; it also relies on having the right technology and skilled people to handle the tasks properly. This means that simply using MLOps tools is not a guaranteed way to productionize AI. Building strong and effective MLOps platforms can be challenging and may not yield the desired results.
Only adding a flavor of MLOps to your project is no guarantee for success.
In this blog post, we’ll discuss six success factors for a successful MLOps platform implementation. Whether you’re just new to MLOps or you’re looking to improve your existing platform, this blog post will provide you with the insights and guidance you need to make your MLOps platform a success. Before we dive into the details, let’s ensure we are all on the same page.
What is MLOps?
As already stated, Machine Learning Operations (MLOps) is a set of practices and, in essence, an engineering culture that combines the development and operations aspects of machine learning/ML. MLOps can be summarised in seven core principles:
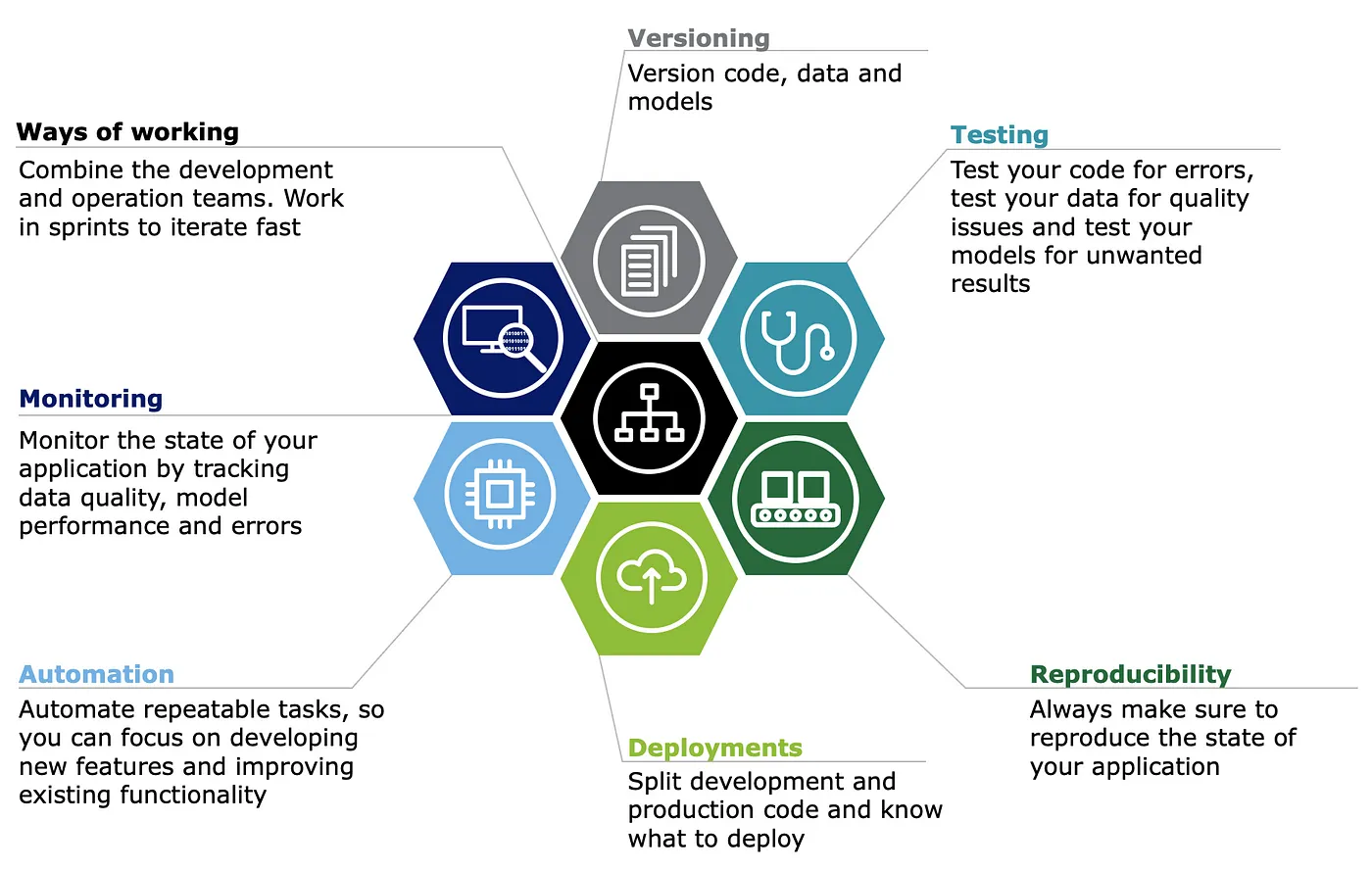
Figure 1: Seven core principles of MLOps, image by author.
You don’t need to fulfill all principles from the start, and there are several services and concepts that facilitate these principles, including:
- An ML experimentation environment with access to raw and curated data
- A feature store to accommodate a generic set of features, including lineage
- Experiment tracking to store results of hyper-parameter optimization
- Model registry to store model artifacts and model lineage
- ML pipelines to operationalize all elements of model training and inference
- Monitoring tools to monitor data and model quality
- CI/CD pipelines for code, data, and models to deploy to several environments
Back to Basics: Shaping Your MLOps Platform
An MLOps platform is the foundation of your AI application, providing the infrastructure necessary for data processing and AI, such as data storage and compute. All services and concepts listed above then run on the platform. Sometimes, an application that consumes the results also runs on the platform, such as a web app. In addition to providing the tooling, the platform facilitates scaling and security for your AI application.
Nowadays, platforms are often built in the cloud. Infrastructure definitions and configurations are stored as code (infrastructure as code, IAC) and developed and deployed using CI/CD principles.
Starting point
Before we start a project to develop an MLOps platform, Let’s begin by defining the following:
- The business problem
- The analytical problem
The business problem originates within the organization and serves as the driving force behind the project. An example can be: “It’s hard to find the correct information in our document management system”.
The analytical problem translates this problem into something that we can solve using an AI product. For instance: “Can we provide the correct information from our document management system by smart interacting with the user and advanced document search using NLP?”.
The analytical problem is the starting point for your project. The final AI solution should be able to address the business problem.
The six success factors
Now that we’re all on the same page, let’s discuss the six success factors:
- Requirements at the start
- Verify the need for an MLOps platform and manage expectations,
- Create a proof of concept,
- Create a design,
- Split the work into iterations,
- Keep the project team motivated.
While some of these success factors may seem obvious, I know from experience that skipping steps can lead to undesirable outcomes.
Success Factor 1: Requirements at the start
Begin by collecting requirements for the AI solution that you intend to build. These requirements are shaped by factors such as business and analytical problems, as well as by the organization, data availability, and existing infrastructure.
To define the requirements, you can ask questions about the solution. Examples include:
- Current situation: what can you reuse from previous projects, and what infrastructure is already available?
- End-users and Future Developers: who will maintain and use the solution in the final state, and what kind of frameworks are they familiar with?
- Data: What is the volume of the incoming data? Is it structured or unstructured? How frequently does new data come in? Can developers and data scientists use production data or is a synthetic data set required?
- Location: What can be hosted in the cloud, what can run locally, or do you need to use edge computing?
- Pre-processing: Do you need to pre-process the data in batch mode or streaming? How do you clean the data? Are there requirements on data lineage, do you need a feature store? Hint: most likely not.
- AI: What models do you need (e.g. rule-based, ML, deep learning, supervised or unsupervised)? How many models do you need to train and use in parallel? Can training and inference be directly connected, or will trained models be applied multiple times to new data? Are there any model lineage requirements?
- Post-processing: Do you need a feedback loop to update data based on model results and user feedback? Do you need to monitor model performance and is there any action required based on the monitor results?
- Consumption: How do you consume the data (e.g. API, web app)? How many use cases do you build on the platform, and do they end up in the same consumption layer?
One source that might be helpful is GitLab’s Jobs To Be Done, which lists the objectives to be achieved with MLOps. In addition to these objectives, critical success factors (CFFs) like delivering on time, staying within budget limits, and meeting quality standards should be considered. It’s also important to identify the technical risks associated with your project, which puts focus on certain aspects of your project and design. Technical risks can be addressed in a proof of concept (POC), as outlined in factor 3. Note that other types of risks, like expected changes in requirements, should be addressed by other risk management techniques.
At this point, you can create an initial design. Later in the project, the design can be refined — more on that in success factor 4. A design illustrates how data and models flow through the applications, and how MLOps enables this process with its services and tools. The design helps in understanding the problem and the solution, gathering requirements, having conversations with stakeholders, and defining the scope of a proof of concept.
Success Factor 2: Verify the Need for an MLOps Platform and Manage Expectations
Not all use cases require an MLOps platform. As running and maintaining a platform is expensive, and resources are scarce it’s advised to double-check its necessity. For example, in some projects, a single trained model integrated into a dashboard can effectively address the business problem — making MLOps redundant. The same analysis applies to the need for a platform. The model and dashboard of the prior example can be packed together and shared with the end user, running on local machines without requiring a platform.
However, our focus is on using AI in production. In my opinion, MLOps platforms are essential when AI is used in production apps. The following, while not exhaustive, outlines the prerequisites of such apps that MLOps can meet:
- AI is used in a production environment, separate from the development environment,
- Development and training are automated and executed in continuous iterations,
- Data lineage and model lineage are necessary,
- A clear view of data quality and model performance is required,
- Certain security requirements must be met.
Once the decision to develop and implement an MLOps platform is made, it’s important to make stakeholders, like product owners and the executive team, aware of the components involved. Typically, stakeholders are primarily interested in the ML aspect, as it directly solves the business issue. The MLOps platform components however are often perceived as non-functional aspects. It’s essential to clarify the investments required in infrastructure and development for building an MLOps platform so that stakeholders understand it’s not a simple task. This way, expectations can be managed from the start, avoiding any surprises down the line.
When you run models in production, it is essential to continuously monitor, update, improve, and deploy them, making the MLOps platform essential — even though it can be costly. Manage stakeholders’ expectations of these investments from the start.
Success Factor 3: Create a proof of Concept
Before starting the real project (such as constructing a platform and developing the AI solution), it is wise to first address the technical risks identified in the first success factor of this blog. These risks can be addressed with a proof of concept (POC).
The POC can focus on the AI component of the solution, which can be the most challenging aspect of the project. This does not only hold for data scientists or ML engineers, but also for key stakeholders who need to be convinced that AI can effectively solve the business problem. Additionally, the POC can be used to test other aspects of the solution such as performance and new services that require evaluation before full implementation. If no technical risks or uncertainties are identified, you can proceed directly to development without the need for a POC.
The POC is a small project in itself, intending to prove to stakeholders that the solution in mind can be built and that it answers the business question. Therefore, it is essential to clearly define the POC’s objective and criteria for success. In other words: what is the concept that needs proof? The focus is on experimenting, hacking, and prototyping. In practice, the POC can consist of code in Jupyter notebooks, with the results presented through a straightforward app, dashboard, or presentation.
If the focus of the POC is on the AI part of the solution, follow the normal data science project steps:
- Identify data sources and get access to them,
- Perform exploratory data analysis,
- Choose the right methodology, such as clustering, object detection, etc.,
- Build, validate, and apply the models,
- Expose the results in a simple application, dashboard, or presentation and verify the results with the stakeholders.
If the focus of the POC is on (parts of) the MLOps platform, it can be used to demonstrate the value of MLOps.
Fast iterations are key: by receiving early feedback, one can explore different approaches. Based on the POC, a go/no-go decision is made for the project.
First prove that your solution solves your problem — before building a platform.
Failing to take this step can be costly: if it turns out that the solution doesn’t address the business question after the full platform has been implemented, a great deal of time and resources are wasted. Also, in the POC phase, it’s easier to change directions than later on in the project.
Success Factor 4: Create a Design
When you defined your requirements (see the first success factor), you already made the first version of a design. Now it is time to bring this to the next level.
Output from this exercise should be architecture diagrams with annotations. Diagrams.net and the markdown format for annotations work well for this purpose. The design can be divided into several levels using the C4 model for software architecture. This way, both high-level building blocks (e.g. offline training, web app) and details and workflows (e.g. experiments run on Jupyter notebooks stored in an experiment tracker) are captured.
There is no need to start from scratch. Cloud providers like AWS, Databricks, and others provide reference architectures and design patterns for different kinds of solutions. For example, Databricks provides The Big Book of MLOps.
The design should cover the implementation of the following components:
- Platform account structure: a root account, monitoring account, and one or more accounts per use case,
- Data storage: database, data warehouse, data lake(house), and feature store,
- Data processing: batch or streaming,
- Model training process: offline or online,
- Model inference process: batch, embedded in stream application, request-response, or deployed to an edge device,
- Continuous integration: git pattern and code quality control,
- Deployments: deployment of code, pipelines, and model artifacts; the storage location for artifacts, and the deployment pattern (blue/green, canary, etc.),
- Data and model pipelines: including the steps (jobs) captured in these pipelines.
Figure 2 shows an example diagram focusing on the AI part of a solution. It uses offline training and batch inference, with data stored in a data lake. It also shows the CI/CD process. In this example, only code is deployed, and models are restrained in the test and production environments.
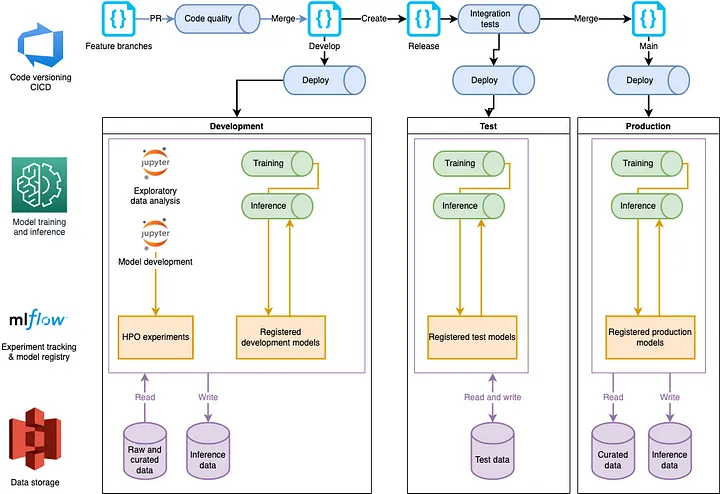
Figure 2: A components design (Level 3 of the C4 model) of the AI training and inference part of the solution. This design shows the implementation of components using managed cloud services. The solution uses offline training and batch inference, with data stored in a data lake. It also shows the CI/CD process. In this example, only code is deployed, and models are retrained in the test and production environment. Image by the author.
Success Factor 5: Split the Work into Iterations
Make a Roadmap
The design from the previous step contains an end-state. Not all features are must-haves from the start, so prioritize and map them. Prioritization is key: not all requirements and features are equally important, and neither are your stakeholders. It is almost impossible to please everyone with the design.
That roadmap is split into iterations, with clear milestones (like epics). To define milestones, one can use the three MLOps maturity levels as defined by Google.
The focus of the first phases must be clearly defined. In later phases, less detailed planning is acceptable. It’s highly likely that the design will change over time due to changing requirements. Additionally, important details that affect the design will only pop up during development.
I prefer iterations or sprints of 2 weeks. For example:
- Start-up phase: let platform engineers launch the first version of the platform that others can build upon (3 sprints)
- Phase 1: First model results shown in client-facing dashboard (8 sprints)
- Phase 2: Data and ML processes are automated using pipelines (8 sprints)
- Phase 3: …
Develop Minimum Viable Products
One can treat the first phases as minimum viable products (MVP). This way you develop a product with few features, yet it does expose results to end users. The end users can validate the results and check if it answers the business and analytical problem framing. The feedback serves as input for the next iterations and phases. It is important to deploy to production as soon as possible so that you can spot any issues there early on. Figure 3 below illustrates the difference between focusing on all aspects of a solution versus considering only the functional foundations.
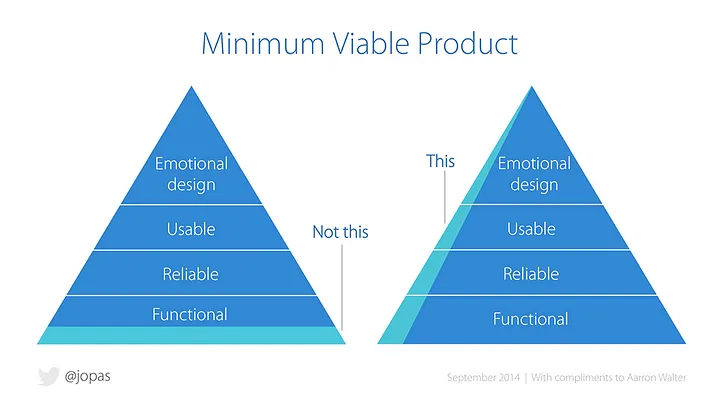
Figure 3: Minimum viable product: build a slice across, instead of one layer at a time. Diagram courtesy of Jussi Pasanen, with acknowledgments to Aarron Walter, Ben Tollady, Ben Rowe, Lexi Thorn, and Senthil Kugalur. Source: https://www.jussipasanen.com/minimum-viable-product-build-a-slice-across-instead-of-one-layer-at-a-time/.
Working this way also ensures that the full team can work simultaneously, as teams downstream are not reliant on the completion of tasks by teams upstream. For instance, the team working on the front end of a web app can already begin development using a dummy dataset. Data scientists can already start modeling with dummy data, rather than waiting for the data engineers to deliver the first cleaned production data. Finally, the first models and results can be deployed to production manually while the deployment pipelines are still being developed.
Focus on developing all components of the solution and deploy models to production promptly. Don’t just concentrate on the MLOps and platform foundations.
Developing MVPs enables rapid iterations. As feedback is frequently received, be prepared to discard features that may no longer be necessary or require modification. Fortunately, due to the quick feedback loops, the amount of rework required is minimal.
While demonstrating the business value of the application is crucial, it’s equally important to allocate time to enhance the application’s robustness by focusing on the non-functional aspects. This can be achieved through a few sprints periodically or a complete project phase to work on testing, monitoring, security, automation, and more, etc. As the importance of these topics may not be clear to all stakeholders, it’s important to include them in sprint demos. This is a great way to educate stakeholders about the comprehensive scope of a project like this.
Success Factor 6: Keep the Project Team Motivated
So far, we have discussed project processes and technology, but let’s not forget about the team. In projects I have been involved in, we usually have the following roles:
- Platform engineers: responsible for developing and deploying the core infrastructure and security,
- MLOps engineers: based on the work of the platform team, responsible for hosting MLOps tools and developing ML pipelines and CI/CD for data and models,
- Data engineers: in charge of data processing, data cleaning, and operationalizing of features feature by building data pipelines,
- Data scientists: focusing on exploring data and creating models,
- Frontend developers: when in scope, UX designers and web app developers to build the frontend,
- Backend developers: focusing on micro-service and API development (if in scope).
Teams can be formed based on the workload for each role. For example, it can be beneficial to create a Platform team and a Data and AI team. The latter includes MLOps engineers, data engineers, and data scientists. Additionally, a team can be dedicated to the web app, containing both backend and frontend developers. In larger projects, each role may have its own team.
Clearly define roles and responsibilities between teams to avoid disappointment.
It’s easy to see that some tasks are obvious about who should take care of them, while others are not so obvious. Two common examples that I’ve frequently encountered are as follows:
- Who is responsible for productionalizing AI models? Data scientists enjoy exploring data and new models but are typically not as passionate about improving code structure. On the other hand, MLOps engineers spending their days cleaning up Jupyter notebooks may not be the most efficient use of their skills. Ideally, MLOps engineers should provide tooling, templates, and a clear structure that allows data scientists to deploy their models with ease. However, this level of maturity is not always present from the start of a project.
- Do all teams have the option to install and use tools and services (on development of course) that they need in order to accomplish their goals, or is this something restricted to the Platform team? Platform engineers will get bored when their backlog gets filled with requests from other teams for new services, and MLOps engineers are blocked when they can’t upgrade the model registry to the latest version themselves. Ideally, the platform offers a self-service approach for new services, but sometimes this is impossible due to security concerns.
In both cases, clear role definitions and managing the expectations of team members are key to keeping the team motivated.